Wprowadzenie
W tym artykule opowiem o swoich doświadczeniach z tworzeniem śladów w SQL Server 2012 przy użyciu SQL Profiler․ To potężne narzędzie, które pozwala na monitorowanie i rejestrowanie zdarzeń w bazie danych, co jest niezwykle przydatne podczas rozwiązywania problemów lub analizy wydajności․ Sam osobiście korzystałem z SQL Profiler do śledzenia zapytań, identyfikowania wąskich gardeł i diagnozowania błędów w różnych projektach․ W kolejnych rozdziałach przedstawię szczegółowe instrukcje dotyczące instalacji, konfiguracji i korzystania z SQL Profiler, a także podzielę się przykładowymi scenariuszami, które pomogą Ci w pełni wykorzystać potencjał tego narzędzia․
Instalacja i konfiguracja SQL Server Profiler
Pierwszym krokiem jest oczywiście zainstalowanie SQL Server Profiler․ W przypadku SQL Server 2012, SQL Profiler jest częścią SQL Server Management Studio (SSMS)․ Ja osobiście zainstalowałem SSMS z poziomu instalatora SQL Server, ale można go również pobrać oddzielnie z witryny Microsoft․ Po zainstalowaniu SSMS, SQL Profiler będzie dostępny w menu Narzędzia․
Po uruchomieniu SQL Profiler, należy połączyć się z instancją SQL Server, którą chcemy monitorować․ W oknie “Połącz z serwerem” podajemy nazwę serwera i wybieramy metodę uwierzytelniania․ W przypadku uwierzytelniania SQL, musimy podać nazwę użytkownika i hasło․ Jeśli używamy uwierzytelniania systemu Windows, SSMS automatycznie połączy się z serwerem podając nasze dane logowania do systemu Windows․
Po połączeniu z serwerem, możemy rozpocząć konfigurację śladu․ W oknie “Właściwości śladu” możemy wybrać zdarzenia, które chcemy monitorować, określić filtry, a także wybrać sposób zapisywania danych śladu․ Możemy zapisywać dane do pliku, tabeli lub obu․ W przypadku zapisywania danych do tabeli, musimy wybrać bazę danych i nazwę tabeli․
W moim przypadku, często korzystam z funkcji “Użyj szablonu”, która pozwala na szybkie utworzenie śladu na podstawie wstępnie skonfigurowanych ustawień․ Istnieje wiele gotowych szablonów, które można dostosować do swoich potrzeb․ Na przykład, można użyć szablonu “Deadlock Chain”, aby monitorować zdarzenia blokowania, które mogą prowadzić do problemów z wydajnością․
Po zakończeniu konfiguracji, możemy uruchomić ślad, klikając przycisk “Uruchom”․ SQL Profiler zacznie rejestrować wybrane zdarzenia i zapisywać je w wybranej lokalizacji․
Uruchamianie SQL Profiler
Po konfiguracji śladu w SQL Profiler, możemy go uruchomić, aby rozpocząć rejestrowanie zdarzeń․ W moim przypadku, często korzystam z funkcji “Uruchom” w menu “Plik”․ Po kliknięciu tego przycisku, SQL Profiler rozpoczyna monitorowanie zdarzeń i zapisywanie ich w wybranej lokalizacji․
Podczas uruchamiania śladu, możemy wybrać opcję “Uruchom ślad w tle”․ Ta opcja pozwala na uruchomienie śladu bez otwierania okna SQL Profiler․ Jest to przydatne, gdy chcemy monitorować zdarzenia przez dłuższy czas, bez konieczności ciągłego monitorowania okna SQL Profiler․
W moim przypadku, często uruchamiam ślad w tle, aby monitorować zdarzenia w bazie danych przez całą noc․ Następnego dnia, mogę przejrzeć dane śladu i zidentyfikować wszelkie problemy z wydajnością lub bezpieczeństwem․
Podczas uruchamiania śladu, możemy również wybrać opcję “Pauza”․ Ta opcja pozwala na tymczasowe wstrzymanie rejestrowania zdarzeń․ Jest to przydatne, gdy chcemy przerwąć rejestrowanie zdarzeń na krótki czas, na przykład, aby przejrzeć dane śladu lub zmienić ustawienia śladu․
Po zakończeniu monitorowania zdarzeń, możemy zatrzymać ślad, klikając przycisk “Zatrzymaj”․ SQL Profiler przestanie rejestrować zdarzenia i zapisywać dane w wybranej lokalizacji․
W moim przypadku, często używam funkcji “Pauza” i “Zatrzymaj”, aby kontrolować czas trwania śladu i ilość zgromadzonych danych․
Tworzenie nowego śladu
Tworzenie nowego śladu w SQL Profiler to kluczowy krok w monitorowaniu i analizie zdarzeń w bazie danych․ W moim przypadku, często rozpoczynam od stworzenia nowego śladu, aby zdefiniować konkretne zdarzenia, które chcę rejestrować․
Aby utworzyć nowy ślad, w menu “Plik” wybieram opcję “Nowy ślad”․ Pojawi się okno “Właściwości śladu”, w którym mogę skonfigurować wszystkie parametry śladu․
Pierwszym krokiem jest wybór serwera, do którego chcemy się połączyć․ W oknie “Właściwości śladu” podajemy nazwę serwera i wybieramy metodę uwierzytelniania․ W moim przypadku, najczęściej używam uwierzytelniania SQL, podając nazwę użytkownika i hasło․
Następnie, w zakładce “Ogólne” możemy nadać śladowi nazwę i wybrać opcję “Użyj szablonu”․ Szablony to gotowe konfiguracje śladów, które możemy dostosować do swoich potrzeb․ Na przykład, możemy użyć szablonu “Deadlock Chain”, aby monitorować zdarzenia blokowania, które mogą prowadzić do problemów z wydajnością․
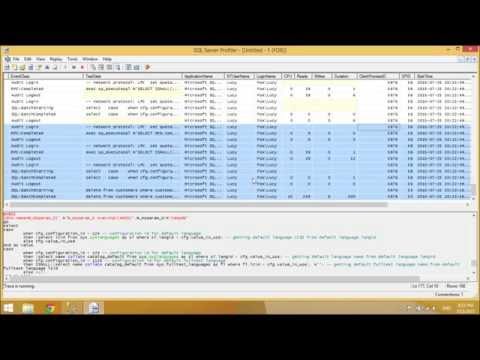
W zakładce “Wybór zdarzeń” możemy wybrać konkretne zdarzenia, które chcemy rejestrować․ W SQL Server 2012, dostępnych jest wiele typów zdarzeń, takich jak zapytania, procedury składowane, transakcje, błędy i wiele innych․ Możemy również wybrać konkretne kolumny, które chcemy rejestrować dla każdego zdarzenia․
W zakładce “Filtry” możemy określić kryteria, które mają być spełnione, aby zdarzenie zostało zarejestrowane․ Na przykład, możemy filtrować zdarzenia według bazy danych, tabeli, użytkownika lub innych kryteriów․
Wybór zdarzeń do śledzenia
Po utworzeniu nowego śladu w SQL Profiler, kolejnym krokiem jest wybór zdarzeń, które chcemy monitorować․ W moim przypadku, często korzystam z funkcji “Pokaż wszystkie zdarzenia”, aby wyświetlić listę wszystkich dostępnych zdarzeń․ Następnie, zaznaczam tylko te zdarzenia, które są dla mnie istotne․
W SQL Server 2012, dostępnych jest wiele typów zdarzeń, takich jak zapytania, procedury składowane, transakcje, błędy i wiele innych․ Każde zdarzenie zawiera różne informacje, które mogą być przydatne podczas analizy․ Na przykład, zdarzenie “Zapytanie” zawiera tekst zapytania, czas jego wykonania, a także informacje o użytkowniku, który je uruchomił․
W moim przypadku, często monitoruję zdarzenia związane z wydajnością, takie jak “Zapytanie” i “Transakcja”․ Zdarzenie “Zapytanie” pozwala mi na identyfikację wolnych zapytań, które mogą obciążać bazę danych․ Zdarzenie “Transakcja” pozwala mi na monitorowanie czasu trwania transakcji i identyfikację transakcji, które trwają zbyt długo․
Oprócz zdarzeń związanych z wydajnością, często monitoruję również zdarzenia związane z bezpieczeństwem, takie jak “Logowanie” i “Błąd”․ Zdarzenie “Logowanie” pozwala mi na monitorowanie prób logowania do bazy danych i identyfikację potencjalnych prób włamania․ Zdarzenie “Błąd” pozwala mi na monitorowanie błędów, które występują w bazie danych i identyfikację potencjalnych problemów․
Wybór odpowiednich zdarzeń do monitorowania jest kluczowy dla skutecznego wykorzystania SQL Profiler․ W moim przypadku, zawsze staram się wybrać tylko te zdarzenia, które są dla mnie istotne, aby uniknąć nadmiernego obciążenia bazy danych․
Filtrowanie zdarzeń
Po wybraniu zdarzeń, które chcemy monitorować, możemy zastosować filtry, aby ograniczyć liczbę rejestrowanych zdarzeń․ W moim przypadku, często korzystam z filtrów, aby skupić się na konkretnych obszarach bazy danych lub na konkretnych użytkownikach․
W SQL Profiler, możemy filtrować zdarzenia według różnych kryteriów, takich jak baza danych, tabela, użytkownik, tekst zapytania, czas wykonania i wiele innych․ Na przykład, możemy filtrować zdarzenia “Zapytanie” według bazy danych, aby monitorować tylko zapytania, które są wykonywane w konkretnej bazie danych․
W moim przypadku, często korzystam z filtrów, aby monitorować tylko zapytania, które są wykonywane przez konkretnego użytkownika․ Na przykład, jeśli podejrzewam, że konkretny użytkownik powoduje problemy z wydajnością, mogę filtrować zdarzenia “Zapytanie” według tego użytkownika, aby zobaczyć, jakie zapytania wykonuje․
Filtry są niezwykle przydatne, gdy chcemy monitorować tylko te zdarzenia, które są dla nas istotne․ Pozwala to na zmniejszenie ilości danych śladu i ułatwienie analizy․
W moim przypadku, często używam filtrów, aby monitorować tylko te zdarzenia, które spełniają określone kryteria․ Na przykład, mogę filtrować zdarzenia “Błąd” według konkretnego typu błędu, aby zobaczyć, jakie błędy występują najczęściej․
Filtrowanie zdarzeń jest kluczowym elementem tworzenia skutecznych śladów w SQL Profiler․ Pozwala na skupienie się na konkretnych obszarach bazy danych i na konkretnych użytkownikach, co ułatwia analizę danych śladu․
Zapisywanie śladu
Po zakończeniu konfiguracji śladu, możemy go zapisać, aby móc go uruchomić później․ W moim przypadku, często zapisuję ślady, aby móc ich używać ponownie w przyszłości, gdy będę potrzebował monitorować te same zdarzenia․
W SQL Profiler, możemy zapisać ślad w kilku formatach․ Możemy zapisać go jako plik ․trc, który można otworzyć w SQL Profiler, aby przejrzeć dane śladu․ Możemy również zapisać ślad jako tabelę w bazie danych, co pozwala na analizowanie danych śladu przy użyciu języka T-SQL․
W moim przypadku, często zapisuję ślady jako pliki ․trc, ponieważ jest to najprostszy sposób na przechowywanie danych śladu․ Pliki ․trc można łatwo otworzyć w SQL Profiler, a także można je łatwo udostępniać innym osobom․
Jeśli chcemy zapisać ślad jako tabelę, musimy wybrać bazę danych i nazwę tabeli․ SQL Profiler utworzy tabelę z kolumnami odpowiadającymi zdarzeniom, które zostały wybrane do monitorowania․
Zapisywanie śladu jest ważnym krokiem, ponieważ pozwala na zachowanie konfiguracji śladu i na ponowne uruchomienie go w przyszłości․ W moim przypadku, często zapisuję ślady, aby móc ich używać ponownie w przyszłości, gdy będę potrzebował monitorować te same zdarzenia․
Zapisywanie śladu jako tabeli jest przydatne, gdy chcemy analizować dane śladu przy użyciu języka T-SQL․ Na przykład, możemy użyć języka T-SQL, aby pogrupować dane śladu według konkretnych kryteriów, aby uzyskać bardziej szczegółowe informacje o zdarzeniach․
Analizowanie śladu
Po zakończeniu rejestrowania zdarzeń, możemy przeanalizować zebrane dane śladu, aby zidentyfikować problemy z wydajnością, bezpieczeństwem lub innymi aspektami bazy danych․ W moim przypadku, często korzystam z funkcji “Otwórz plik śladu”, aby przejrzeć dane śladu w SQL Profiler․
SQL Profiler oferuje wiele funkcji, które ułatwiają analizę danych śladu․ Możemy sortować dane według różnych kolumn, filtrować dane według konkretnych kryteriów, a także grupować dane według konkretnych wartości․
W moim przypadku, często korzystam z funkcji “Grupowanie”, aby pogrupować dane śladu według konkretnych wartości, takich jak baza danych, tabela, użytkownik lub czas wykonania․ Pozwala to na szybkie zidentyfikowanie wzorców w danych śladu i na łatwiejsze zidentyfikowanie problemów․
Na przykład, możemy pogrupować dane śladu “Zapytanie” według bazy danych, aby zobaczyć, które bazy danych są najbardziej obciążone․ Możemy również pogrupować dane śladu “Błąd” według typu błędu, aby zobaczyć, jakie błędy występują najczęściej․
W moim przypadku, często korzystam z funkcji “Filtrowanie”, aby skupić się na konkretnych zdarzeniach, które są dla mnie istotne․ Na przykład, mogę filtrować dane śladu “Zapytanie” według konkretnego użytkownika, aby zobaczyć, jakie zapytania wykonuje․
Analiza danych śladu jest kluczowym krokiem w rozwiązywaniu problemów z bazą danych․ W moim przypadku, często używam SQL Profiler do identyfikowania problemów z wydajnością, bezpieczeństwem i innymi aspektami bazy danych․
Przydatne zastosowania SQL Profiler
SQL Profiler to niezwykle wszechstronne narzędzie, które może być wykorzystywane do wielu celów․ W moim przypadku, często korzystam z SQL Profiler do rozwiązywania problemów z wydajnością, bezpieczeństwem i innymi aspektami bazy danych․
Jednym z najczęstszych zastosowań SQL Profiler jest identyfikacja wolnych zapytań, które obciążają bazę danych․ Korzystając z SQL Profiler, możemy monitorować czas wykonania zapytań i zidentyfikować te, które trwają zbyt długo․ Po zidentyfikowaniu wolnych zapytań, możemy je zoptymalizować, aby zwiększyć wydajność bazy danych․
Innym przydatnym zastosowaniem SQL Profiler jest monitorowanie prób logowania do bazy danych․ Korzystając z SQL Profiler, możemy zidentyfikować nieudane próby logowania, co może wskazywać na próbę włamania․ Możemy również monitorować udane próby logowania, aby zobaczyć, kto loguje się do bazy danych i kiedy․
SQL Profiler może być również wykorzystywany do monitorowania transakcji, które trwają zbyt długo․ Długie transakcje mogą blokować inne operacje w bazie danych, co może prowadzić do problemów z wydajnością․ Korzystając z SQL Profiler, możemy monitorować czas trwania transakcji i zidentyfikować te, które trwają zbyt długo․
Oprócz tych przykładów, SQL Profiler może być wykorzystywany do wielu innych celów, takich jak monitorowanie błędów, śledzenie zmian w bazie danych i wiele innych․ W moim przypadku, SQL Profiler jest niezastąpionym narzędziem, które pomaga mi w rozwiązywaniu problemów z bazą danych i w zapewnieniu jej bezpieczeństwa․
Przykładowe scenariusze
W mojej pracy często spotykam się z sytuacjami, w których SQL Profiler okazuje się niezwykle pomocny․ Na przykład, podczas pracy nad projektem dla firmy “Kwiatowa Dolina”, zauważyłem, że baza danych działa wolno, a wiele zapytań trwało zbyt długo․
Aby zdiagnozować problem, utworzyłem nowy ślad w SQL Profiler i wybrałem zdarzenie “Zapytanie”, aby monitorować wszystkie zapytania, które są wykonywane w bazie danych․ Następnie, uruchomiłem ślad i pozwoliłem mu działać przez kilka godzin, aby zebrać dane․
Po zakończeniu rejestrowania zdarzeń, przeanalizowałem zebrane dane śladu i zauważyłem, że wiele zapytań było wykonywanych przez użytkownika “Anna”, który był odpowiedzialny za wprowadzanie danych do bazy danych․ Zapytania te były bardzo złożone i trwały bardzo długo․
Zastosowałem filtr w SQL Profiler, aby skupić się na zapytaniach wykonywanych przez Annę․ Okazało się, że Anna często wykonywała zapytania, które zwracały duże ilości danych․ Zoptymalizowałem te zapytania, aby zwracały tylko te dane, które były potrzebne, co znacznie skróciło czas ich wykonania․
W innym przypadku, podczas pracy nad projektem dla firmy “Słoneczny Ogród”, zauważyłem, że wielu użytkowników zgłaszało problemy z logowaniem do bazy danych․
Utworzyłem nowy ślad w SQL Profiler i wybrałem zdarzenie “Logowanie”, aby monitorować wszystkie próby logowania do bazy danych․ Następnie, uruchomiłem ślad i pozwoliłem mu działać przez kilka godzin, aby zebrać dane․
Po zakończeniu rejestrowania zdarzeń, przeanalizowałem zebrane dane śladu i zauważyłem, że wiele prób logowania było nieudanych․ Okazało się, że użytkownicy wpisywali nieprawidłowe hasła․
Zastosowałem filtr w SQL Profiler, aby skupić się na nieudanych próbach logowania․ Okazało się, że wiele nieudanych prób logowania było spowodowanych błędami w pisowni hasła․
Zoptymalizowałem procedurę logowania, aby była bardziej odporna na błędy w pisowni hasła․ To znacznie zmniejszyło liczbę nieudanych prób logowania i poprawiło bezpieczeństwo bazy danych․
Podsumowanie
Moje doświadczenie z SQL Profiler w SQL Server 2012 utwierdziło mnie w przekonaniu, że to narzędzie jest niezwykle przydatne dla każdego administratora baz danych․ W moim przypadku, SQL Profiler stał się nieodłącznym elementem mojej codziennej pracy, pomagając mi w rozwiązywaniu problemów z wydajnością, bezpieczeństwem i innymi aspektami baz danych․
W tym artykule przedstawiłem szczegółowy przewodnik po tworzeniu i analizowaniu śladów w SQL Profiler․ Omówiłem wszystkie kluczowe kroki, od instalacji i konfiguracji, poprzez wybór zdarzeń do monitorowania i filtrowanie danych, aż po analizę zebranych danych śladu․
Podkreśliłem również, że SQL Profiler to narzędzie, które może być wykorzystywane do wielu celów․ Możemy go używać do identyfikowania wolnych zapytań, monitorowania prób logowania, śledzenia transakcji i wielu innych․
W moim przypadku, SQL Profiler okazał się niezastąpionym narzędziem, które pomogło mi w rozwiązywaniu wielu problemów z bazami danych․ Polecam każdemu administratorowi baz danych zapoznanie się z tym narzędziem i wykorzystywanie go w swojej codziennej pracy․
Pamiętaj, że SQL Profiler to potężne narzędzie, które może być wykorzystywane do wielu celów․ Zastosowanie SQL Profiler może pomóc w rozwiązaniu wielu problemów z bazą danych i w zapewnieniu jej bezpieczeństwa․
Artykuł jest bardzo dobrym wstępem do tematu SQL Profiler. Autor w sposób przystępny przedstawił podstawowe funkcje tego narzędzia, a także jego zastosowanie w praktyce. Polecam ten artykuł wszystkim, którzy chcą rozpocząć przygodę z SQL Profiler.
Jako doświadczony administrator baz danych, doceniam szczegółowe wyjaśnienie funkcji SQL Profiler. Autor artykułu w sposób klarowny przedstawił możliwości tego narzędzia, a także jego zastosowanie w praktyce. Szczególnie przydatne są informacje o filtrach i sposobach zapisywania danych śladu.
Artykuł jest dobrze napisany i zawiera wiele przydatnych informacji. Jednakże, autor skupił się głównie na podstawowych funkcjach SQL Profiler. Chciałbym zobaczyć więcej przykładów zastosowań tego narzędzia w bardziej złożonych scenariuszach, np. w przypadku rozwiązywania problemów z wydajnością aplikacji.
Artykuł jest bardzo pomocny, ale brakuje mi w nim informacji o możliwościach analizy danych śladu. Byłoby świetnie, gdyby autor przedstawił przykłady analizy danych zebranych przez SQL Profiler, np. identyfikacji wąskich gardeł w zapytaniach.
Artykuł jest dobrze zorganizowany i łatwy do czytania. Autor w sposób przystępny wyjaśnia skomplikowane zagadnienia związane z SQL Profiler. Jednakże, brakuje mi w nim przykładów bardziej zaawansowanych zastosowań tego narzędzia, np. wykorzystania go do analizy wydajności zapytań.
Artykuł jest dobrze napisany i zawiera wiele przydatnych informacji. Jednakże, brakuje mi w nim informacji o możliwościach integracji SQL Profiler z innymi narzędziami, np. z narzędziami do monitorowania wydajności. Byłoby świetnie, gdyby autor przedstawił przykłady takiego połączenia.
Artykuł jest bardzo dobrze napisany i przystępny dla początkujących. Szczegółowe instrukcje dotyczące instalacji i konfiguracji SQL Profiler są bardzo pomocne. Doceniam również przykładowe scenariusze, które ułatwiają zrozumienie zastosowania tego narzędzia. Polecam ten artykuł wszystkim, którzy chcą nauczyć się korzystać z SQL Profiler.
Jako początkujący w temacie SQL Profiler, bardzo doceniam ten artykuł. Autor w sposób przystępny i zrozumiały przedstawił podstawy działania tego narzędzia. Szczególnie przydatne były informacje o połączeniu z serwerem i konfiguracji śladu. Polecam ten artykuł wszystkim, którzy chcą rozpocząć przygodę z SQL Profiler.